AI Learn¶
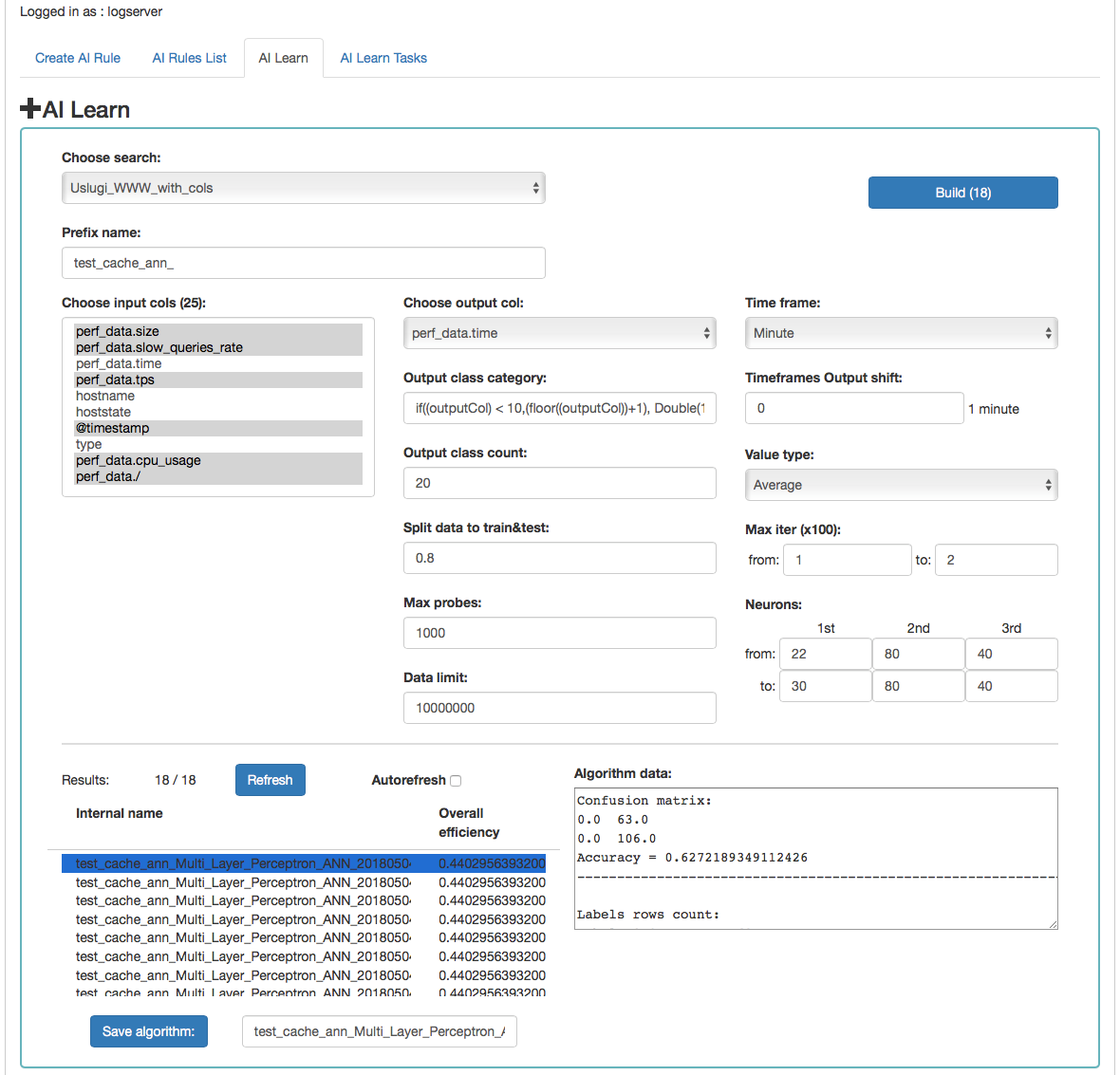
Description of controls:
- Search - a source of data for teaching the network
- prefix name - a prefix added to the id of the learned model that allows the user to recognize the model
- Input cols - list of fields that are analyzed / input features. Here, the column that will be selected in the output col should not be indicated. Only those columns that are related to processing should be selected. **
- Output col - result field, the recognition of which is learned by the network. This field should exist in the learning and testing data, but in the production data is unnecessary and should not occur. This field cannot be on the list of selected fields in “input col”.
- Output class category - here you can enter a condition in SQL
format to limit the number of output categories e.g.
if((outputCol) \< 10,(floor((outputCol))+1), Double(10)). This condition limits the number of output categories to 10. Such conditions are necessary for fields selected in “output col” that have continuous values. They must necessarily by divided into categories. In the Condition, use your own outputCol name instead of the field name from the index that points to the value of the “output col” attribute. - Time frame - a method of aggregation of features to improve their quality (e.g. 1 minute, 5 minutes, 15 minutes, 30 minutes, 1 hour, 1 daily).
- Time frames output shift - indicates how many time frame units to move the output category. This allows teaching the network with current attributes, but for categories for the future.
- Value type - which values to take into account when aggregating for a given time frame (e.g. maximum from time frame, minimum, average)
- Output class count- the expected number of result classes. If during learning the network identifies more classes than the user entered, the process will be interrupted with an error, therefore it is better to set up more classes than less, but you have to keep in mind that this number affects the learning time.
- Neurons in first hidden layer (from, to) - the number of neurons in the first hidden layer. Must have a value > 0. Jump every 1.
- Neurons in second hidden layer (from, to) - the number of neurons in second hidden layer. If = 0, then this layer is missing. Jump every 1.
- Neurons in third hidden layer (from, to) - the number of neurons in third hidden layer. If = 0 then this layer is missing. Jump every 1.
- Max iter (from, to) - maximum number of network teaching repetitions (the same data is used for learning many times in internal processes of the neural network). The slower it is. Jump every 100. The maximum value is 10, the default is 1.
- Split data to train&test - for example, the entered value of 0.8 means that the input data for the network will be divided in the ratio 0.8 to learning, 0.2 for the tests of the network learned.
- Data limit - limits the amount of data downloaded from the source. It speeds up the processing, but reduces its quality.
- Max probes - limits the number of samples taken to learn the network. Samples are already aggregated according to the selected “Time frame” parameter. It speed up teaching but reduces its quality.
- Build - a button to start teaching the network. The button contains the number of required teaching curses. You should be careful and avoid one-time learning for more than 1000 courses. It is better to divide them into several smaller ones. One pass after a full data load take about 1-3 minutes on a 4 core 2.4.GHz server. The module has implemented the best practices related to the number of neurons in individual hidden layers. The values suggested by the system are optimal from the point of view of these practices, but the user can decide on these values himself.
Under the parameters for learning the network there is an area in which teaching results will appear.
After pressing the “Refresh” button, the list of the resulting models will be refreshed.
Autorefresh - selecting the field automatically refreshes the list of learning results every 10s.
The following information will be available in the table on the left:
- Internal name - the model name given by the system, including the user - specified prefix
- Overall efficiency - the network adjustment indicator - allow to see at a glance whether it is worth dealing with the model. The grater the value, the better.
After clicking on the table row, detailed data collected during the learning of the given model will be displayed. This data will be visible in the box on the right.
The selected model can be saved under its own name using the “Save algorithm” button. This saved algorithm will be available in the “Choose AI Rule” list when creating the rule (see Create AI Rule).